Black-Box Model Extraction — Stealing AI Without Touching the Weights
Introduction
Today we are going to discuss the “Model Extraction” TTP, which has some new and very real impact on the industry as of today.
On March 31, 2026, security researcher Chaofan Shou posted on X: "Claude code source code has been leaked via a map file in their npm registry."
Within hours, Anthropic's entire Claude Code codebase — 512,000 lines of TypeScript across 1,900 files, including multi-agent orchestration systems, unreleased feature pipelines, internal model codenames, and architectural decisions that took years to develop — was mirrored across GitHub and analyzed by thousands of developers. The repository surpassed 1,100 stars and 1,900 forks before Anthropic could respond.
The attack vector wasn't sophisticated. It was a .map file.
When you bundle JavaScript/TypeScript for production, source map files are generated as debugging artifacts — they map compiled output back to original source. Anthropic's build pipeline, using Bun as the runtime, generated source maps by default and accidentally included a 59.8MB .map file in version 2.1.88 of the @anthropic-ai/claude-code npm package. Anyone who ran npm install @anthropic-ai/claude-code could download the complete source.
This is ML05, model and IP theft. This wasnt executed through clever API queries or gradient attacks, but through a misconfigured .npmignore. It's the third time Anthropic has made this exact mistake. Earlier versions v0.2.8 and v0.2.28 from 2025 had the same issue.
Model theft doesn't always look like a sophisticated adversarial attack. Sometimes it looks like a build pipeline oversight that costs you your roadmap.
The Threat Landscape: Real-World IP Theft Incidents
Before getting into extraction methodology, it's worth cataloging how AI IP theft actually happens in practice — because the attack surface is much broader than most might think.
Incident 1: The Claude Code Source Map Leak (March 31, 2026)
What was exposed goes beyond embarrassment. The leaked code revealed:
Internal model codenames: Capybara (Claude 4.6 variant), Fennec (Opus 4.6), Numbat (unreleased). For competitors, this is an intelligence windfall, you now know Anthropic's model naming conventions, what's in testing, and specific weaknesses (a 29-30% false claims rate in Capybara v8, a regression from v4's 16.7%).
"Undercover Mode": A subsystem designed to prevent internal information from leaking in git commits. Anthropic built a whole feature to stop their AI from revealing internal codenames; then shipped the codenames in a .map file.
Unreleased product pipeline: BUDDY (companion agent), KAIROS (always-on Claude), ULTRAPLAN (30-minute remote planning), and multi-agent "swarms" coordinator mode; all feature-gated in external builds but fully present in source maps.
Architectural decisions worth years of R&D: The query engine (46K lines), the tool system (29K lines of base tool definitions alone), the IDE bridge using JWT-authenticated channels, the persistent memory system design.
Security vulnerability amplification: Because the leak revealed the exact orchestration logic for Hooks and MCP servers, attackers can now design malicious repositories specifically crafted to abuse Claude Code's trust model before a user ever sees a trust prompt.
Anthropic's statement: "Earlier today, a Claude Code release included some internal source code. No sensitive customer data or credentials were involved or exposed. This was a release packaging issue caused by human error, not a security breach."
The concurrent timing is worth noting: the same day as the source map leak, the axios npm package was hit by a supply chain attack (versions 1.14.1 and 0.30.4 contained a Remote Access Trojan). If you installed or updated Claude Code between 00:21 and 03:29 UTC on March 31, 2026, audit your lockfiles immediately.
Incident 2: Meta's LLaMA Weight Leak (March 2023)
Meta released LLaMA under controlled academic access to select researchers. Within seven days, a complete copy of the model weights appeared on 4chan and spread across GitHub and BitTorrent networks. The attack vector: a single authorized researcher shared the weights publicly, bypassing the noncommercial license entirely.
Within weeks, dozens of fine-tuned variants appeared, BasedGPT and others optimized for tasks Meta never intended. IP that Meta tried to control became commodity software. Meta filed DMCA takedowns; copies continued spreading. The traditional IP enforcement model assumes centralized control. AI model weights don't fit that model.
Incident 3: Clearview AI's Facial Recognition Model (2021)
Clearview AI's facial recognition system; trained on billions of scraped images and representing years of development was stolen by attackers who gained database access. Unlike the LLaMA case, this was a direct infrastructure breach, not an insider leak. The stolen model had been trained on data Clearview itself had questionably obtained, which added a second layer of legal complexity to the breach. The model theft compounded an already-contested IP position.
Incident 4: The OpenAI Distillation Concern (2025)
In July 2025, OpenAI reportedly introduced significantly stricter internal security controls including aggressive compartmentalization, biometric access to sensitive labs, deny-by-default networking, and partially air-gapped infrastructure specifically in response to concerns about rivals using model distillation techniques on ChatGPT outputs. In other words: using the public API to systematically extract model behaviors and use them to train competing models.
OpenAI has not publicly confirmed a specific breach, but the security response is itself evidence of the threat model. The concern wasn't a single sophisticated heist, it was systematic API querying by well-resourced actors using query-based extraction at scale.
Why Query-Based Model Extraction Works
Setting aside the leak and insider threat scenarios above, the core technical attack is worth understanding deeply: extracting a functional approximation of a model purely through API queries.
ML models are function approximators. They map inputs to outputs. If you observe enough (input, output) pairs, you can train another model to approximate the same function; without access to architecture, weights, or training data.
Three properties make this practical:
Determinism. Given the same input, a deployed model produces the same (or statistically similar) output. Systematic querying is reliable.
Learnable decision boundaries. You don't need to know how the model decides you need enough samples of what it decides to train a substitute that makes the same decisions.
Rich API outputs. Most production APIs return more than just the predicted class. Confidence scores, probability distributions, ranked outputs, or generated text — all dramatically increase the information content per query. The Carlini et al. (2024) paper "Stealing Part of a Production Language Model" demonstrated extracting structural properties of production LLMs purely from their outputs at scale.
Attack Methodology
Phase 1: Reconnaissance
Understand what you're attacking before querying:
What inputs does the model accept? (text, images, structured data, code)
What does the output look like? (single class, probability distribution, generated text)
Are there rate limits? (defines your query budget and timing strategy)
Is there anomaly detection? (affects query diversity requirements)
Is the base model known? (if you can identify the architecture, you can initialize your substitute from the same base)
For the Claude Code case: the leaked source now tells you exactly what queries are processed, how they're tokenized, and what model variants serve which requests. Post-leak, a competitor's extraction attack would be dramatically more efficient.
Phase 2: Seed Dataset Construction
Build a query set that spans the input space. For a text classifier:
import requests
import time
from typing import List, Dict
TARGET_API = "https://api.target-model.com/classify"
def generate_seed_queries(domain: str = "text_classification", n: int = 1000) -> List[str]:
"""
Generate queries that span the input space.
Goal: coverage across all input types, not just obvious cases.
"""
seeds = []
# For a spam classifier: cover all realistic message types
templates = [
"Professional email templates",
"Marketing messages",
"Meeting requests",
"Financial notices",
"Social messages",
"Technical documentation",
"Customer support tickets",
# Edge cases near decision boundary are most valuable
"Ambiguous promotional content",
"Legitimate win notifications",
]
for template_type in templates:
queries = generate_diverse_samples(template_type, n // len(templates))
seeds.extend(queries)
return seeds
def harvest_oracle_responses(queries: List[str]) -> List[Dict]:
"""Harvest (input, output) pairs from the target oracle."""
harvest = []
for i, query in enumerate(queries):
response = requests.post(TARGET_API, json={"text": query})
result = response.json()
harvest.append({
"input": query,
"output": result["predicted_class"],
"probabilities": result.get("probabilities"), # Gold if available
"confidence": result.get("confidence"),
})
# Stay under rate limits — vary timing
time.sleep(0.1 + (0.05 * (i % 3)))
return harvest
Phase 3: Adaptive Boundary Exploration
Random sampling is inefficient. Samples near the decision boundary — where the model is uncertain — carry the most information about where that boundary lies. Map it precisely.
def find_boundary_samples(harvest: List[Dict], threshold: float = 0.15) -> List[Dict]:
"""
Identify samples near the decision boundary (high uncertainty).
These are the most informative samples for training a substitute.
"""
boundary_samples = []
for sample in harvest:
if sample.get("probabilities"):
# Near-50/50 split = near decision boundary
probs = list(sample["probabilities"].values())
uncertainty = 1 - max(probs)
if uncertainty > (0.5 - threshold):
boundary_samples.append(sample)
return boundary_samples
def adaptive_boundary_exploration(
boundary_sample: Dict,
perturbation_fn,
target_api,
n_perturbations: int = 20
) -> List[Dict]:
"""
Given a near-boundary sample, generate perturbations to map
the local decision boundary precisely.
"""
perturbations = perturbation_fn(boundary_sample["input"], n_perturbations)
results = []
for perturbed in perturbations:
response = target_api.classify(perturbed)
results.append({
"input": perturbed,
"output": response.predicted_class,
"probabilities": response.probabilities,
"is_boundary": abs(response.probabilities[0] - 0.5) < 0.1,
})
return results
Phase 4: Substitute Model Training
Train a substitute on harvested oracle labels. The substitute doesn't need to share the original's architecture, it needs to approximate its behavior.
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score
import numpy as np
import json
def train_substitute_model(harvested_data: List[Dict]):
"""
"""
texts = [h["input"] for h in harvested_data]
# Use oracle's probability outputs as soft labels if available
if harvested_data[0].get("probabilities"):
soft_labels = np.array([
list(h["probabilities"].values()) for h in harvested_data
])
y = np.argmax(soft_labels, axis=1)
else:
y = np.array([
1 if h["output"] == "spam" else 0 for h in harvested_data
])
vectorizer = TfidfVectorizer(max_features=10000, ngram_range=(1, 2))
X = vectorizer.fit_transform(texts)
substitute = MultinomialNB(alpha=0.1)
substitute.fit(X, y)
return substitute, vectorizer
def evaluate_fidelity(
substitute, vectorizer,
test_queries: List[str],
target_api
) -> Dict:
"""
Fidelity: what fraction of the time does the substitute
agree with the oracle on unseen inputs?
This is more meaningful than accuracy — we care about
behavioral equivalence, not ground-truth accuracy.
"""
agreements = 0
total = len(test_queries)
for query in test_queries:
oracle_class = target_api.classify(query).predicted_class
X = vectorizer.transform([query])
sub_class = "spam" if substitute.predict(X)[0] == 1 else "ham"
if oracle_class == sub_class:
agreements += 1
return {
"fidelity": agreements / total,
"n_test_queries": total,
"interpretation": "behavioral agreement with oracle on unseen inputs"
}
Phase 5: Operational Use
A working substitute model enables:
Rate limit evasion: Query your local substitute freely. Hit the production API only for ground-truth validation on edge cases.
Adversarial example generation: Generate adversarial inputs against the substitute. Due to transferability, they often fool the original.
IP theft / competing service: Offer the same capability at zero training cost.
Safety bypass research: Map the safety classifier's decision boundary locally. Understand exactly what inputs the model classifies as unsafe and stay below that threshold.
Pre-exploitation reconnaissance: Use the substitute to understand the model's behavior before crafting targeted attacks against the production system.
The LLM Extraction Problem — And What the Claude Code Leak Changes
Extracting a traditional classifier via API queries is tractable. Fully extracting a frontier LLM is a different problem in scale — but not necessarily in kind.
For LLMs, the practical extraction goals are:
System prompt extraction: Covered in depth in the prompt injection series. The leaked Claude Code source now reveals exactly how system prompts are structured, what variables they contain, and how they're constructed programmatically.
Behavioral fingerprinting: Harvesting enough output pairs to understand the model's distribution — useful for crafting effective adversarial prompts and jailbreaks.
Capability cloning via distillation: Training a smaller model on outputs from a larger one. This is specifically what OpenAI tightened infrastructure against in 2025. The research term is "model distillation" — using a large model as a teacher to train a smaller student. Done without authorization, it's IP theft via query.
Fine-tuning data extraction: Using membership inference and careful prompting to extract examples from the model's fine-tuning dataset. Particularly relevant for models fine-tuned on proprietary corpora.
The Claude Code leak specifically changes the threat model for the last two. Before the leak, an attacker trying to extract Claude Code's agentic behavior had only black-box access, they had to infer the orchestration model from behavior alone. Post-leak, the exact system prompts used by the coordinator mode, the tool permission architecture, and the query engine design are all available as a blueprint. A well-resourced actor could use the leaked source to dramatically reduce the query cost of behavioral cloning.
The Taxonomy of AI IP Theft
Pulling together the real-world cases and the technical attack, the full taxonomy:
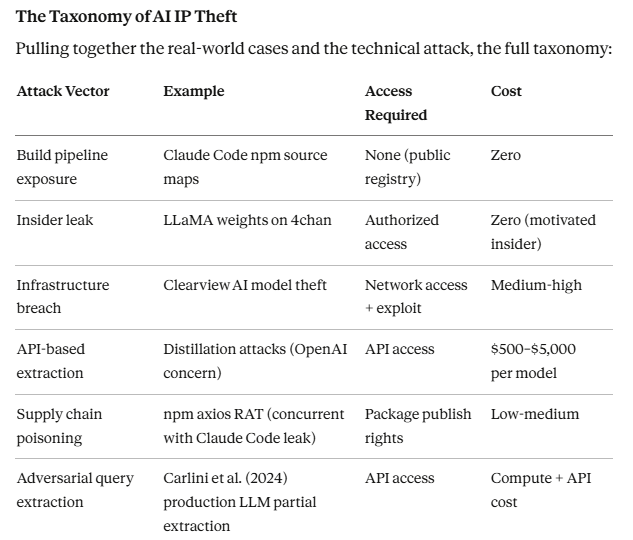
The build pipeline exposure is the category that keeps happening and gets underweighted in threat models. Source maps, exposed .git directories, misconfigured cloud storage buckets, accidentally committed secrets; these may not be sophisticated attacks, but being sophisticated to the point of being sophisticated just because doesnt get the same amount of impact. The impact here is potentically big. The Claude Code incident being the third time Anthropic made this specific mistake is the most instructive detail in this entire story.
The Concurrent Supply Chain Attack
The axios supply chain attack occurred hours before the Claude Code source leak was disclosed.
Axios versions 1.14.1 and 0.30.4 contained a Remote Access Trojan via a dependency called plain-crypto-js. Anyone who ran npm install or npm update between 00:21 and 03:29 UTC on March 31 may have installed a compromised version.
If you installed or updated Claude Code on March 31, 2026:
grep -A2 "\"axios\"" package-lock.json grep -A2 "axios:" yarn.lock grep "plain-crypto-js" package-lock.json yarn.lock bun.lockb # If found — treat the host as compromised: # 1. Rotate all secrets and API keys accessible from that machine # 2. Revoke any tokens that were live during the window # 3. Full OS reinstallation before trusting the machine again
Two supply chain attacks in the same day, one targeting the same package ecosystem. This is not coincidence — this is what the attack surface looks like when a high-value developer tool with broad access to codebases and credentials becomes a target.
Detection and Defense
For defenders: what extraction attacks look like in API logs:
High query volume from single source or small source set
Systematically diverse queries (no contextual continuity between them)
Query distribution concentrated near decision boundaries
Absence of normal user behavior patterns (no typos, unusual formality, systematic coverage)
Large volume of low-confidence queries (boundary exploration)
Defensive controls (with honest effectiveness ratings):
Rate limiting: Necessary, insufficient. Attackers distribute queries across IPs, use multiple accounts, or simply slow their exfiltration rate. Raises cost, doesn't prevent.
Output restriction: Returning only the predicted class rather than full probability distributions significantly raises the query cost of extraction: each query yields less information, requiring more queries to train an equivalent substitute. One of the most cost-effective defenses.
Query anomaly detection: Statistical analysis of query patterns to identify systematic exploration. Requires investment in monitoring infrastructure but provides early detection of extraction campaigns.
Model output watermarking: Embedding statistical watermarks in outputs that persist in any extracted substitute. This enables attribution; if you find a model that responds with your watermark, it was extracted from yours. Active research area with promising results.
Build pipeline hygiene (the lesson from today):
npm pack --dry-run echo "*.map" >> .npmignore bun build --sourcemap=none src/index.ts --outdir dist/
Red Team Assessment Checklist
When assessing an organization's AI IP protection posture:
Build pipeline and distribution:
Are source maps excluded from all published packages?
Are model weights and artifacts stored with appropriate access controls?
Is there access logging on model weight storage?
Are CI/CD secrets (training credentials, API keys) rotated regularly?
API security:
Does the API return full probability distributions, or only predicted classes?
Are there rate limits per API key, IP, and user account?
Is there anomaly detection on query patterns?
Are model outputs watermarked for attribution?
Insider threat:
Are model weights in access-controlled repositories with audit logs?
Is there offboarding procedure for researchers with model access?
Are access permissions reviewed on regular cadence?
Supply chain:
Are npm dependencies pinned to specific versions with hash verification?
Is there automated scanning for malicious dependency additions?
Are lockfiles committed and verified in CI/CD?
Where to Practice — Labs and CTF Resources
Understanding this TTP on paper is one thing. The only way to actually build intuition for what extraction looks like in practice, the query patterns, the fidelity numbers, the boundary exploration behavior is to run it yourself. Below is a curated map of every platform that has hands-on labs for model extraction and related ML attack techniques, ordered by how directly they cover this TTP.
Dreadnode Crucible: Best Direct Coverage
Crucible is the closest thing to a dedicated AI red teaming dojo, and it has a specific model extraction category. The platform is free, browser-based, and the challenges run against live API endpoints rather than contrived sandboxes.
The Bear Series is the recommended entry point for this TTP specifically. Bear3 covers model extraction — querying a black-box API, analyzing the outputs, and inferring the model's internal structure without direct access. Bear4 covers model fingerprinting — identifying and characterizing a deployed model based purely on its output behavior, building a fingerprint that distinguishes one model from another. Both challenges come with Jupyter notebook walkthroughs.
The full challenge catalog also includes model evasion, adversarial image and audio manipulation, membership inference, data poisoning, and system prompt leakage: a complete adversarial ML curriculum against live targets.
Dreadnode was founded by Will Pearce and Nick Landers, who are legitimate names in offensive AI security. Their AIRTBench research (which benchmarks AI models against Crucible challenges) demonstrates Claude 3.7 Sonnet solving 61% of the challenge suite: useful context on the difficulty ceiling.
Microsoft AI Red Teaming Playground Labs + PyRIT
Originally taught at Black Hat USA 2024, these labs are tied to Microsoft's open-source PyRIT framework (Python Risk Identification Tool for Generative AI). Released as a public GitHub repo, referenced in the Microsoft Learn AI Red Teaming 101 series (10 episodes, free, July 2025).
The honest assessment on coverage: the playground labs themselves focus on prompt injection (single-turn and multi-turn), indirect injection via a mock webpage, automating attacks with PyRIT, and implementing mitigations. There is no dedicated model extraction challenge in the lab set.
What is relevant here is PyRIT itself. The framework explicitly supports simulating model extraction attacks to assess how easily a model's functionality can be duplicated. You can point PyRIT at your own model endpoint or local Ollama deployment and run systematic extraction queries with built-in logging and scoring. It also supports model inversion and membership inference attack simulation.
The MathPromptConverter (one of 61 built-in converters) transforms user queries into symbolic math problems — directly applicable to the token smuggling and obfuscation techniques that make extraction queries less detectable by input-side guards.
AI Village CTF @ DEFCON: Archived, Solvable
The AI Village CTF is the longest-running adversarial ML competition series, run annually at DEFCON via Kaggle. The challenge taxonomy explicitly includes a "Steal" category: interacting with the model API to learn about its structure and find a way to recreate it. In traditional hacking you might exfiltrate a model binary, but in these challenges you interact with the API, exactly the black-box extraction methodology covered in this blog post.
Both the DEFCON 30 and DEFCON 31 competitions are archived on Kaggle and remain solvable as self-paced challenges. Community writeups exist for most challenges.
SaTML 2024 LLM CTF (ctf.spylab.ai)
Run as part of the SaTML 2024 conference. The focus was on system prompt extraction and whether prompting/filtering mechanisms can make LLMs robust to injection and extraction attacks. The full dataset: 72 defenses and 144,838 adversarial chat logs is now public, making it a research-grade resource for understanding what extraction attempts actually look like at volume.
More relevant to the system prompt exfiltration angle than model weight extraction, but the extraction methodology overlaps directly with what's covered in this post.
HackThisAI (GitHub): Self-Hosted
The original adversarial ML CTF challenge set that shaped the DEFCON competitions. No longer maintained but still functional. Categories include Steal (model extraction), Evade (adversarial examples), Influence (data poisoning), and Membership Inference. Each challenge is a self-contained Jupyter notebook — no platform registration required, runs locally.
Good for offline lab work on Kali or an air-gapped machine. Lower production quality than Crucible but fully self-contained.
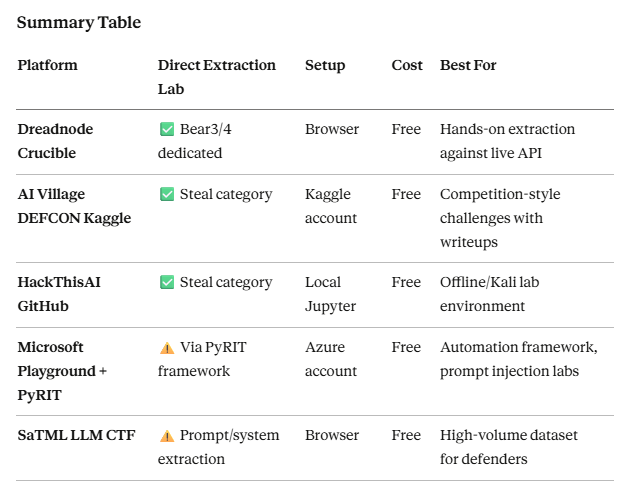
Recommended learning path: Start with Dreadnode Crucible Bear3/4 for the dedicated extraction walkthrough. Use the AI Village DEFCON archives for additional challenge variety and community writeups. Integrate PyRIT for automation once you understand the manual methodology — being able to run systematic extraction queries programmatically and log/score results is the operational skill that translates to real engagements.
Conclusion
Model extraction is the IP theft attack of the AI era. It doesn't always require sophisticated adversarial techniques. Sometimes it's a .map file in an npm package. Sometimes it's an authorized researcher with a public internet connection. Sometimes it's a well-resourced competitor who's willing to spend a few thousand dollars on API calls.
The Claude Code incident is instructive beyond the technical details: a company building AI security tooling, with dedicated internal systems to prevent information leakage, exposed its entire proprietary codebase through a build configuration oversight. For the third time.
Security is hard. Build pipelines are harder. But npm pack --dry-run is free.
The asymmetry of AI IP theft is real — training a frontier model costs hundreds of millions of dollars. Extracting a functional approximation of its behavior costs API credits. Accidentally exposing the source costs nothing at all.
As organizations invest further in proprietary AI assets, protecting those assets — through API design, build pipeline hygiene, access controls, anomaly detection, and watermarking — is not optional. It's as critical as protecting your production database.
References
Tramèr, F., Zhang, F., Juels, A., Reiter, M. K., & Ristenpart, T. (2016). Stealing Machine Learning Models via Prediction APIs. 25th USENIX Security Symposium (USENIX Security 16), pp. 601–618. Austin, TX. https://www.usenix.org/conference/usenixsecurity16/technical-sessions/presentation/tramer
Carlini, N., Paleka, D., Dvijotham, K., Steinke, T., Hayase, J., Cooper, A. F., Lee, K., Jagielski, M., Nasr, M., Conmy, A., Yona, I., Wallace, E., Rolnick, D., & Tramèr, F. (2024). Stealing Part of a Production Language Model. ICML 2024 (Best Paper). arXiv:2403.06634. https://arxiv.org/abs/2403.06634
Haselton, T. (2026, March 31). Claude Code's source code appears to have leaked: here's what we know. VentureBeat. https://venturebeat.com/technology/claude-codes-source-code-appears-to-have-leaked-heres-what-we-know
Shou, C. [@Fried_rice]. (2026, March 31). Claude code source code has been leaked via a map file in their npm registry! [Post]. X .
Anhaia, G. (2026, March 31). Claude Code's Entire Source Code Was Just Leaked via npm Source Maps — Here's What's Inside. DEV Community. https://dev.to/gabrielanhaia/claude-codes-entire-source-code-was-just-leaked-via-npm-source-maps-heres-whats-inside-cjo
OWASP Foundation. (2023). OWASP Top 10 for Machine Learning Security: ML05 — Model Theft. OWASP Gen AI Security Project. https://genai.owasp.org/llmrisk2023-24/llm10-model-theft/
Anthropic. (2026). Claude Sonnet 4.6 [Large language model]. https://claude.ai
Used for: research synthesis, code examples, and reference compilation throughout this post.