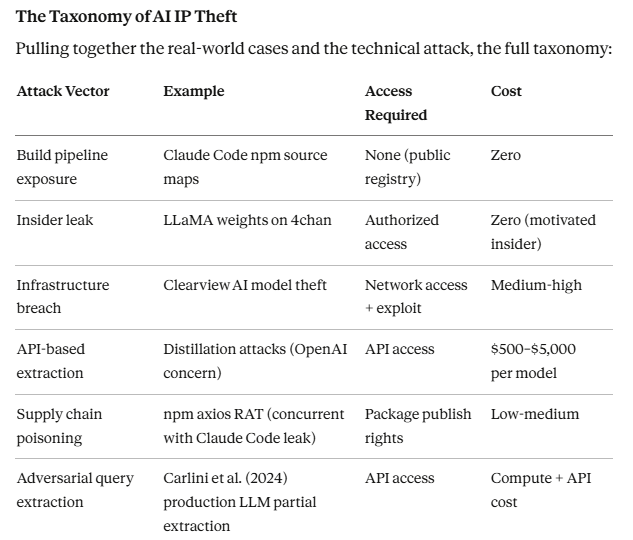
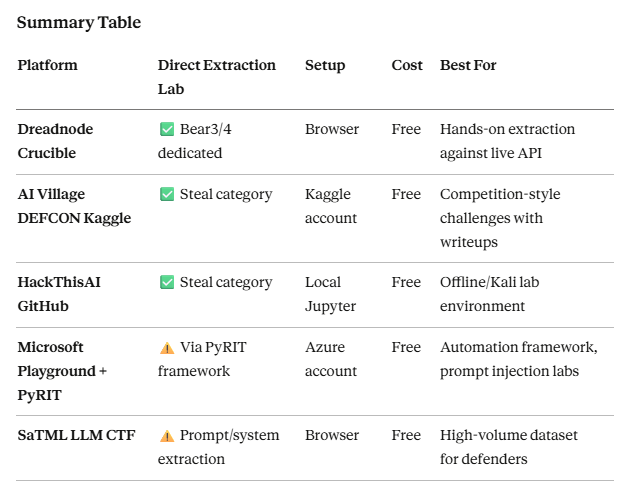
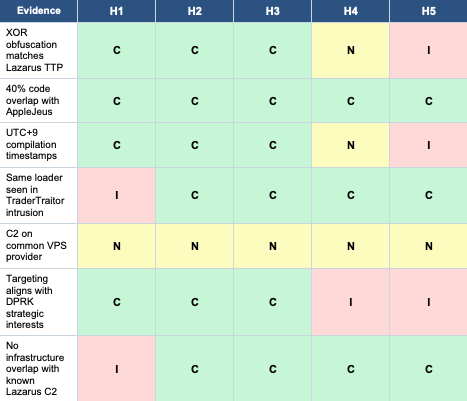
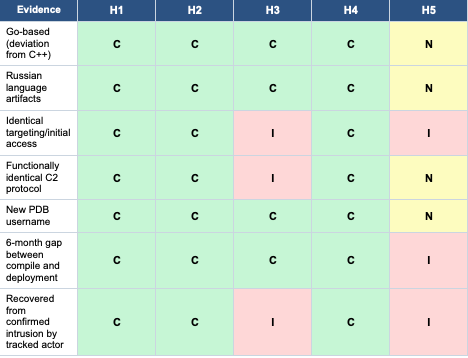
[un]promoted 2026 — Talk Summaries
03 · Heather Adkins & Four Flynn — Evaluating Threats & Automating Defense at Google
Google's ambition to eliminate every software vulnerability on Earth using AI. They've built two systems: Big Sleep (agentic vulnerability discovery that finds deep bugs classical fuzzing misses — already has ~178 fixes) and Code Mender (automated patching pipeline). The workflow: LLM reasons about the codebase, generates exploit PoCs, runs them, gets feedback, iterates, then produces a verified patch with a high-quality report for the developer. Key challenge is verification — they use formal methods, fuzzing pre/post-patch, and functionality checks. NVD has a 30K backlog; this is aimed at closing that gap autonomously without human intervention in the loop.
04 · Joshua Saxe — The Hard Part Isn't Building the Agent: Measuring Effectiveness
The real blocker for autonomous AI security systems isn't building them — it's evaluating them. Classic ML metrics (precision/recall/F1) break down for agentic tasks because ground truth in security is inherently noisy (human experts disagree at double-digit rates on whether alerts are real). Proposes a rubric-based holistic evaluation approach modeled on hiring interviews: grade agents on whether they gathered the right evidence, reasoned correctly, made the right decision, and explained it clearly. Argues that without rigorous evals, you can't safely deploy autonomous cyber defense — you're just flying on vibes. Also covers how to use LLM-as-judge with calibration against domain experts.
05 · Shruti Datta Gupta & Chandrani Mukherjee — Security Guidance as a Service (Adobe)
Adobe's two-person team built a RAG-based system to democratize security guidance across their entire engineering org. Developers get consistent, vetted, org-specific security answers whether they're in Slack, Jira, or their IDE (Cursor via MCP server). The pipeline: document ingestion → embeddings → vector store → LLM orchestrator → formatted response. Key lessons: document freshness is critical (they run evals and diff-checks on source docs), eval pipelines are non-negotiable, and making security "zero calorie" for developers drives adoption. Also integrated with Jira for automated vulnerability remediation guidance.
06 · Jeffrey Zhang & Siddh Shah — Guardrails Beyond Vibes (Stripe)
Built two AI security agents at Stripe: a threat modeling agent and a security routing agent. Core problem: LLM outputs are non-deterministic, so you can't just vibe-check quality. They built a semantic equivalence eval pipeline (using AlphaEvolve/LLM-as-judge) to measure accuracy across prompt changes. Key learnings: garbage prompt → garbage output; agent architecture matters (modular multi-agent beat single monolithic); JSON formatting issues killed 10% accuracy; threat modeling is art not science so there's no single "right" answer. Required humans in the loop for final approval. Phased rollout + shadow mode before full production release.
07 · Paul McMillan & Ryan Lopopolo — Code Is Free: Securing Software (OpenAI)
Practical philosophy: code is now free, so stop treating security as a bottleneck. Encode all your security expertise, past PR feedback, and tribal knowledge into your codebase as security.md, agents.md, and inline threat models — then have coding agents (Codex) enforce them on every PR autonomously. Use agents to run dependency reputation checks, supply chain analysis, and guardrail validation in CI. The key insight: your job as a security engineer shifts from writing policies to distilling your expertise into prompts and codebase artifacts that agents can act on at scale. Also covered: package manager hardening, post-install script blocking, and telemetry for tracking agent behavior.
08 · Brendan Dolan-Gavitt & Vincent Olesen — Agents Exploiting "Auth-by-One" Errors
Novel approach to automated authorization/IDOR bug finding using AI agents. The core trick: give an agent two auth contexts (low-privilege user + admin), have it probe endpoints, and look for differential responses. That differential is your oracle — if the low-priv request gets back what only admin should see, you found a bug. They also handle authentication bypasses (JWT forging from hardcoded keys, parameter manipulation like admin=1), MFA bypasses, and session issues. Built a validator system to confirm exploitation succeeded. Demo'd on Redmine with a real IDOR. Key insight: you don't need to teach the agent auth from scratch — the differential response IS the signal.
09 · Natalie Isak & Waris Gill — Developing & Deploying AI Fingerprints (Microsoft)
BinaryShield — a cross-service prompt injection correlation system for large orgs with multiple AI products. Problem: each service has its own safety stack and can't share raw prompts across service boundaries due to privacy. Solution: 4-step pipeline — strip PII → generate embedding → quantize to binary (0/1) via hamming distance → add differential privacy noise → publish fingerprint to shared registry. When Service Alpha catches an attack, it broadcasts the binary fingerprint; Services Beta/Gamma can match against it without ever seeing the actual prompt. Trade-off: privacy budget (epsilon) controls noise level — more privacy = less correlation accuracy. Demonstrated 36x speed improvement over dense embedding search.
10 · Sean Park — When Passports Execute: Exploiting AI-Driven KYC Pipelines
Live demo of indirect prompt injection via passport/ID document images in KYC pipelines. Attacker embeds malicious instructions in document fields (passport text, authority fields). The AI extraction agent reads the document, follows the injected instructions, and exfiltrates data from the connected SQLite database or writes malicious records. Key challenge: building semantically diverse injection prompts — a single prompt that works one day may not work the next, so used Claude to generate 200 varied prompts tested against 13 models. Recommended defenses: read-only DB access, encrypt column names, validate at the data layer not the prompt layer. Also discussed using sub-agents to keep context windows small and improve reliability.
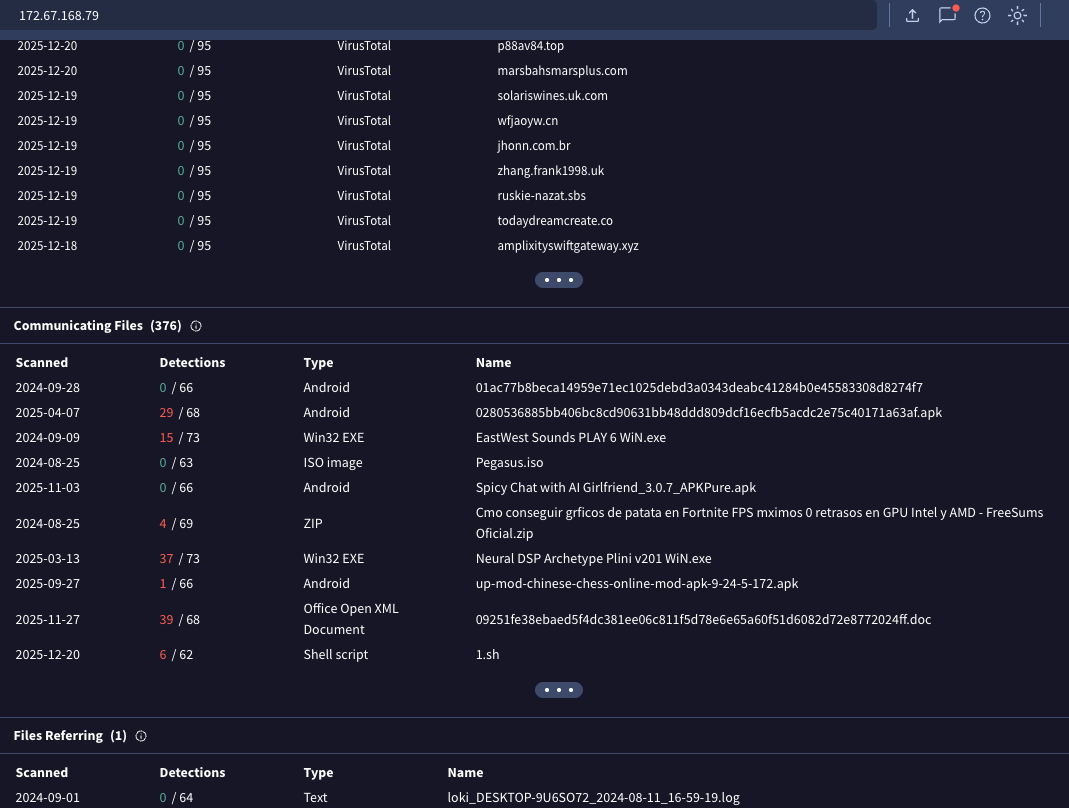
11 · Peter Girnus & Derek Chen — FENRIR: AI Hunting for AI Zero-Days at Scale (Trend Micro)
Production-scale zero-day discovery engine targeting AI/ML frameworks (LangChain, etc.). Cascade architecture: YARA/semgrep → CQL → LLM L1 triage (fast, biased toward recall) → LLM L2 deep agentic analysis (Opus, multi-turn, full sandbox with code execution) → human review. Key results: 60+ CVEs filed, ~$0.61 median cost per true positive, 2.5x throughput increase, 70% faster disclosure timelines vs. traditional research. Dynamic token allocation across stages. The L1 triage must never drop true positives; false positives are fine at that stage. Reflection prompting keeps models honest. Demo showed a live scan with a real finding during the talk.
12 · Joe Sullivan — AI Notetakers: The Most Important Person in the Room
Former Uber/Meta CISO sounding the alarm on AI meeting recorders (Otter, Granola, etc.) becoming a massive, underappreciated security risk. Key issues: attorney-client privilege destruction (judge ruled "your conversations with Claude are not privileged"), trade secret exposure, recording consent laws, prompt injection via meeting content, data retention unknowns, and the fact that the AI notetaker now has full context on every sensitive conversation in your company. Real-world example: a CISO got fired after an employee secretly recorded him. The notetaker is now "the most important person in the room" because it shapes what gets remembered and surfaced. Call to action: security teams need policies NOW before wearables (Meta glasses, etc.) make this even harder.
13 · Adam Laurie (Major Malfunction) — AI go Beep Boop
Hardware hacking demo of using Claude to democratize voltage glitching for firmware extraction. The Raiden Pico project: a ~$7 Raspberry Pi Pico as a disposable glitching platform replacing $1,000+ FPGA rigs. Demo'd extracting firmware from a readout-protected chip using electromagnetic fault injection. Claude's role: answered the three key glitch parameters (where, when, how hard), wrote the ADC measurement code, helped reverse engineer the timing, and ported code across platforms. Key message: AI has made hardware hacking accessible to hobbyists and lowered the barrier from nation-state-level capability to anyone with $7 and curiosity. The Raiden Pico is open-source.
14 · Rami McCarthy — Zeal of the Convert: Taming Shai-Hulud with AI
Practical threat intelligence tradecraft using AI for large-scale supply chain attack attribution. Case study: the Singularity/SHY-HULUD npm supply chain attack affecting 30K victims and 37 of the Fortune 100. Key workflow: collect → analyze with AI (identify data shape, extract signals) → build deterministic rules → feed back loop. Critical lessons: don't replace deterministic methods with AI — use AI to generate better deterministic rules; flat files + AI beat feeding 30GB to context windows; reasoning models excel at pattern recognition and attribution from encoded data (JWTs, environment variables); inject skepticism to prevent AI from hallcinating confident-sounding wrong answers; build composable throwaway tools rather than reinventing pipelines. The "RPI loop": iterative AI-assisted analysis cycles until exit criteria.
15 · Daniel Miessler — Anatomy of an Agentic Personal AI Infrastructure
Demo of Daniel's personal AI stack built on Claude Code + custom skills/agents. Key components: Council (two debate agents argue a position, main agent synthesizes), Iterative Depth (scientific method loop for research questions), PI Upgrade (monitors package releases, auto-drafts upgrade PRs), Label & Rate (surfaces highest-signal content from all sources), and Surface (OSINT recon pipeline — subdomains → ports → fingerprinting). Central thesis: the future is everyone having a personal AI infrastructure that filters reality for them, amplifies their capabilities, and handles recurrent tasks. Companies will become APIs. Security implications: if your AI system is compromised, everything it touches is compromised. Argues for discrete, testable, SOP-driven agent design over monolithic agents.
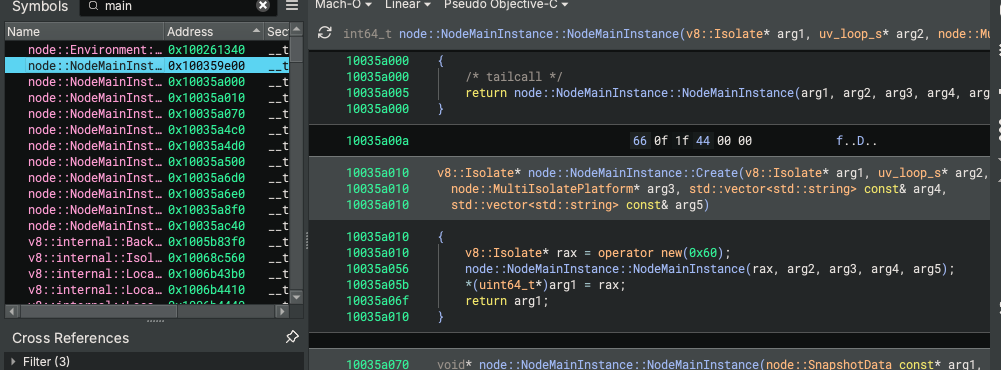
16 · Nicholas Carlini — Black-Hat LLMs (Anthropic)
The most technically sobering talk of the conference. Carlini (vulnerability researcher at Anthropic) presented evidence that LLMs are now finding real, novel, exploitable vulnerabilities in production software — Linux kernel heap overflows, NFS protocol implementation bugs, smart contract exploits, SQL injection in CMS platforms. Key data: models can complete tasks that take humans ~15 hours; capability is doubling every ~4 months on security benchmarks; the most recent models can find bugs that older models couldn't. Live demo: Claude Code autonomously finding and exploiting a Ghost CMS blind SQL injection with no scaffolding. The concern isn't malicious use (safeguards exist) — it's the transitionary period where attackers adopt faster than defenders can patch. Call to action: the security community needs to help Anthropic find and fix bugs FASTER, because the window is closing.
17 · Piotr Ryciak — Vibe Check: Security Failures in AI-Assisted IDEs (Mindgard)
Systematic security research across 40+ AI-assisted IDEs (Cursor, Claude Code, Gemini CLI, Amazon Kiro, Codeex, etc.), finding 37 vulnerabilities across 9 categories. The four attack primitives: prompt injection (hidden instructions in repo files), file read (agents indexed and exfiltrated secrets), config poisoning (malicious MCP configs in workspace), URL fetching (external callbacks). Attack chains: victim clones malicious repo → opens in IDE → agent reads adversarial directory name or index.md → follows attacker instructions → reverse shell / secret exfiltration. Key finding: workspace trust models are universally broken — approval fatigue, race conditions (code executes before trust dialog shows), trust not re-prompted on config changes. Proposed baseline: deny trust by default, reprompt on config changes, hash-based integrity checks. MCP servers run outside sandbox = persistent attack surface.
18 · Gadi Evron — Closing Words
Conference organizer closing remarks. Noted ~800 attendees, praised Salesforce as the sponsor, thanked speakers and volunteers. Community-building theme: security + AI practitioners forming a cohesive community. Happy hour announced.
19 · Billy Norwood — Establishing AI Governance Without Stifling Innovation (FFF Enterprises)
CISO of a $5B pharmaceutical distribution company sharing how they built AI governance from scratch. Key structure: AI Center of Excellence committee (CISO, CIO, legal, compliance, data science), risk-tiered intake form (low/medium/high based on PHI, PII, financial data exposure), Databricks as central AI platform and "system of context" (not system of record). Use cases: medical pre-auth automation ($250K saved), pharmacy compliance workflows, SAP/Salesforce data integration via orchestrator agents. Lessons: governance needs executive sponsorship early; shadow AI will happen anyway so build secure on-ramps; acceptable use policy + training reduces risk more than blocking; secure browsers help corral shadow AI; human-in-loop requirements scale with risk level.
20 · Ragini Ramalingam — Enterprise AI Governance at Snowflake
Head of enterprise security at Snowflake on governing AI at an AI-first engineering company where the CEO wants everything yesterday. Core framework: visibility first (you can't govern what you can't see — deployed endpoint/network/DLP/CASB to discover all AI tools), then feature-based risk assessment (not tool-based), then dynamic control planes that evolve as fast as vendor feature releases. Key shift: traditional governance assumed deterministic execution (defined logic → predictable output); AI agents are non-deterministic (one prompt can trigger arbitrary system calls, file reads, network egress). Solution: constrain execution authority at the agent level, not just access level. Cross-functional steering committee with real executive authority is essential. Weekly syncs with vendors to stay ahead of feature releases. Governance must move at the speed of AI or it becomes irrelevant.
21 · Chase Hasbrouck — Three Phases of AI Adoption (US Army Cyber Command)
LTC from Army Cyber Command sharing the DoD/Army AI adoption arc. Phase 1: Shadow AI era — soldiers using ChatGPT on personal devices, building CamoGPT (Army's internal GPT wrapper), Llama 2 on-prem experiments (largely failed — models too weak). Phase 2: Enterprise platforms — JAI.mil (DoD-wide AI platform), enterprise agreements, Copilot rollout, but token scarcity and bureaucratic procurement cycles created bottlenecks (burned monthly tokens by day 1). Phase 3: Now — agentic workflows, MCP integrations, specialized models for specific domains (malware analysis, SIGINT). The "silo reflex" problem: every unit wants their own specialized box instead of contributing to a shared platform. Key challenge: classification requirements effectively prohibit the most valuable use cases at the SECRET+ level. Bottom line: same adoption battles as every enterprise, just with extra paperwork and lives on the line.
Hell of a conference. The through-lines across all talks: eval rigor is the unsolved problem, MCP/agentic attack surface is exploding, governance needs to move at the speed of AI, and Carlini's talk is the one that should keep everyone up at night.
[un]promoted 2026 — Batch 2 Talk Summaries
32 · Gadi Evron — Opening Words (Day 2)
Conference organizer opening for Day 2. ~700 attendees online, ~550 in-person. Key themes: the shift to nondeterministic systems (coding agents, MCP) is creating auditability and traceability problems that security hasn't caught up to yet. "Citizen coders" bypassing SSO, vibe-coding their way into production — CISO, finance, devs, HR all now have AI agents. Gadi's provocation: if you haven't looked at the AI changelog in your enterprise every week, you're already behind. The conference is forming into a community, which is the real value.
22 · Rob T. Lee — SIFT-FIND-EVIL: I Gave Claude Code R00t on the DFIR SIFT Workstation
SANS founder demo: gave Claude Code root access on the SIFT DFIR workstation with a claude.md orchestrator file that knows all the SIFT tools. Result: a complete intrusion analysis of a compromised Windows image (C drive + memory) in 18 minutes, producing a full professional report with executive summary, timeline, IOCs, and malware inventory. Normally takes 2-3 days of manual analysis. Key workflow: cloud.md defines tools → agent runs volatility, Plaso, event log analyzers, network forensics tools autonomously → compiles report. Announced a SIFT hackathon/competition with $10K+ prize pool. Main limitation discussed: context rot on large disk images — need to manage context windows carefully with sub-agents or chunking.
23 · Mika Ayenson — "Can You See What Your AI Saw?" (Elastic)
Detection engineering perspective on the AI IDE/agent observability gap. Current telemetry sees processes spawning (cursor, claude, node, bash) but not why — no visibility into the prompts, tool calls, or reasoning. Gaps: you see the git commit but not that it was AI-generated; you see the subprocess but not the prompt that triggered it; you miss grandchildren processes below the parent. Proposed detection signals: unusual ancestry trees from AI processes, config file modification (.cursor/, claude.md, MCP configs), credential file access, unexpected network calls from IDE processes, agent hook telemetry (pre/post tool call events). The industry needs full chain observability: prompt → tool call → output → file system effect. Shared Elastic detection rules. MCP server spawning outside sandbox is a specific detection opportunity.
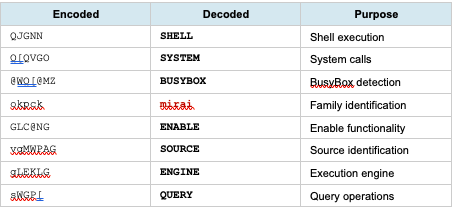
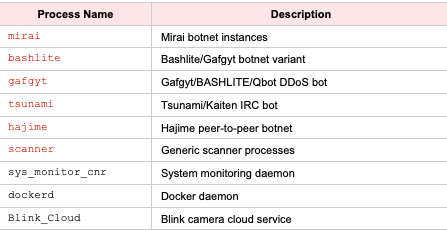
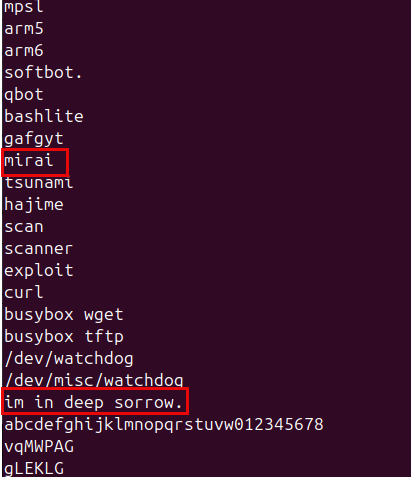
24 · Mohamed Nabeel — Detecting GenAI Threats at Scale with YARA-Like Semantic Rules (Palo Alto)
Introduced SuperYara — an open-source framework that extends YARA with semantic/LLM-based conditions for detecting GenAI threats (prompt injections, malicious AI-generated content, clickfix attacks, etc.). Architecture: standard YARA atoms as a cheap pre-filter → if matched, call LLM condition for semantic judgment → classifier layer. Key design: cascade filtering (cheapest rule first, only invoke expensive LLM if pre-filter passes) achieves ~99% cost reduction vs. pure LLM analysis. The library is pluggable — swap any LLM backend. Demo'd detecting a clickfix attack where JavaScript deobfuscation required semantic understanding that classic YARA couldn't handle. Achieves 4.5 second average detection time. Fully open source on GitHub (pip install superyara).
25 · Aaron Grattafiori & Skyler Bingham — Tenderizing the Target (NVIDIA)
End-to-end AI-powered offensive security pipeline for automated vulnerability discovery and exploitation in production codebases. Workflow: ingest target codebase → architecture analysis → CWE-based vulnerability triage → proof-of-concept generation → build/test loop → verified exploit. The "tenderizing" metaphor: systematically softening defenses by understanding the target deeply before injecting. Key components: skills system (reusable attack modules), sub-agent parallelism (multiple vulnerability classes tested simultaneously), anti-reward hacking measures (avoid gaming evals), and build harnesses that confirm actual code execution. Current limitations: still weak at business logic vulns; models sometimes refuse PoC generation; needs latest frontier models. Not open source but described the architecture for building similar systems. Practical note: inject CWE context into prompts rather than free-form "find vulns" for better signal.
26 · Matt Maisel — Hooking Coding Agents with the Cedar Policy Language (Cindera)
Using Cedar (AWS's open-source policy language) as a deterministic guardrail layer for coding agents. Problem: can't rely solely on LLM safeguards — need an always-invoked, tamperproof, auditable enforcement layer. Architecture: hook every agent action (plan, generate, execute, tool call) as events → Cedar policy engine evaluates attributes (user identity, file path, operation type, environment context) → allow/deny. Enables information flow control (taint tracking: mark a secret as confidential, prevent it from being written to a log), trajectory-aware policies (block dangerous actions only after certain prior actions occurred), and multi-turn stateful guardrails. Cedar is expressive, fast, and formally analyzable — policies can be machine-checked for correctness. Demo'd blocking environment variable harvesting and destructive SQL queries without WHERE clause. Open sourced example policies. Complements sandbox systems, not replaces them.
27 · Carl Hurd — Glass-Box Security: Operationalizing Mechanistic Interpretability
Applying mechanistic interpretability (reading model internals via activations) as a new class of security detection. Instead of looking at inputs/outputs, look at what's activated inside the model during inference. Key concept: capture latent space activations at specific layers to detect malicious intent before it manifests in output — e.g., detect "file deletion intent" or "credential exfiltration intent" as a high-confidence activation pattern regardless of how the prompt is phrased. Uses cosine similarity against known-bad activation manifolds. Challenges: activations aren't available in closed-source APIs (cloud models); dimensionality is enormous; requires per-model calibration; can't be universal. For open-source/fine-tuned models this is tractable today. Analogous to building YARA rules but for neural activation patterns. Called for building a community of "glass-box security" researchers analogous to malware analysts.
28 · Maxim Kovalsky — The AI Security Larsen Effect: How to Stop the Feedback Loop
The "Larsen effect" (audio feedback loop) analogy for AI security vendor evaluation spiraling into noise. Problem: customers arrive with "we need AI security," get pitched 40 overlapping vendors, buy multiple tools with redundant capabilities, then need more tools to manage the first tools. Built AdjusterIQ — a tool to help security architects map business requirements to vendor capabilities systematically. Workflow: define use cases → map to risk taxonomy (Palo Alto/MITRE-inspired) → evaluate vendors against capability matrix → identify gaps → recommend buy/build/partner decisions. Demo'd using Claude Code to scrape vendor API docs and capability claims, score them, surface gaps. The tool flags when vendors claim capabilities they can't actually deliver. Main takeaway: start with use cases, not vendor lists — let requirements drive tool selection, not marketing slicks. Open sourced on GitHub.
30 · Aaron Brown & Madhur Prashant — Trajectory-Aware Post-Training Security Agents
Technical deep-dive on RL-based post-training of LLMs for security tasks (pen testing, CTF, code analysis). Problem: base models are decent at atomic tasks but fail at long-horizon security workflows because they lack security-specific behavioral training. Solution: define a verifiable reward (did you get the flag? did the exploit succeed?), set up a live environment (containers with vulnerable apps), run the agent, collect trajectories, optimize via GRPO/REINFORCE. Key challenges: reward hacking (model games the metric without solving the actual task), compute cost (multi-turn long-horizon RL is expensive), and generalization (trained on CTFs, may not transfer to real-world apps). Used Qwen 3 as base model; after training on CyBench, went from ~0% to solving multiple previously-unsolvable challenges. Framework: Open Trajectory (open source, collects agent traces in common format). Tools mentioned: SkyRL, Unsloth, VerlX. Key lesson: eval design is 80% of the work.
31 · Adam Krivka & Ondrej Vlcek — AI Found 12 Zero-Days in OpenSSL
Isle (AI Security Lab Engine) — their production vulnerability research pipeline found 12 CVEs in OpenSSL including stack overflows, memory corruption, and logic bugs in TLS components. Architecture: two-phase — broad exploration (generate as many hypotheses as possible) followed by deep narrowing (verify and prove exploitability). The pipeline: static analysis → context construction → LLM triage → agentic deep analysis with code execution sandbox → human review for final CVE submission. Key insight: LLMs excel at historical pattern matching — they've seen similar bug classes across millions of codebars and can hypothesize likely vulnerable code patterns. False positive rate is kept low by requiring the model to self-dispute findings before human review. Also working on automated remediation. The OpenSSL team (Matt Caswell) was initially skeptical; now collaborating. Being applied to other high-prominence open source projects. CVE hub available at isle.ai.
33 · Rob Lee, Glenn Thrope, Dan Hubbard, Sergej Epp — Vibe Coded (Panel/Demo)
Closing panel + demo session. Rob demo'd a conference agenda app vibe-coded in 8 minutes using Lovable to make the point about how fast useful tools can be built. Panel discussion covered: the democratization of exploit building (if finding CVEs is getting as cheap as commodity research, what changes?); how DFIR timelines are collapsing from weeks to hours; the need to meet offensive AI speed with defensive AI speed. Hubbard noted exploit-to-patch timelines are already shrinking. Key call to action: the fundamental economics of security are changing — the question isn't whether to use AI, it's whether you're building the muscle to verify, validate, and integrate it responsibly. Audience poll: ~3% had already vibe-coded a security tool at the conference.
38 · Gadi Evron on behalf of Zenity — PleaseFix
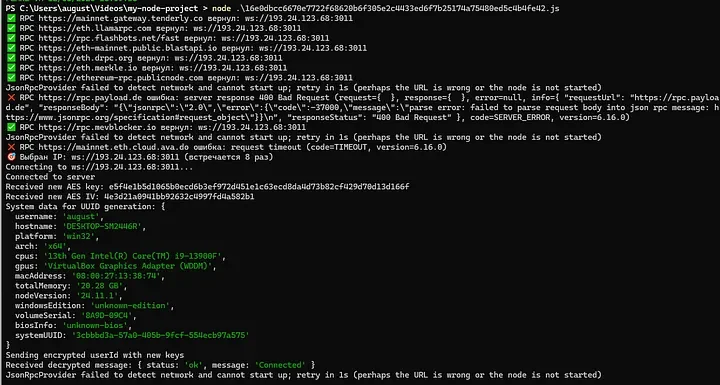
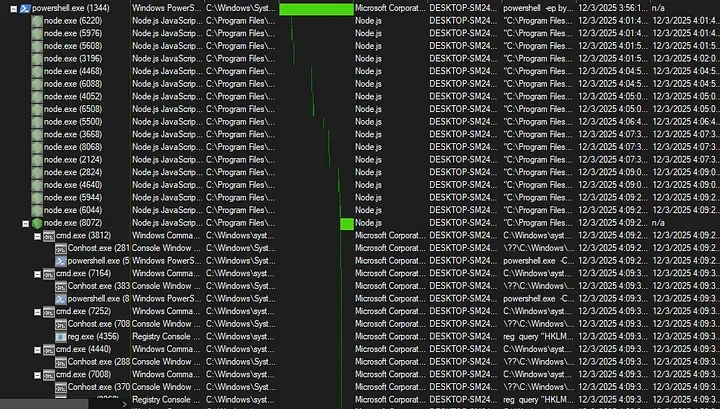
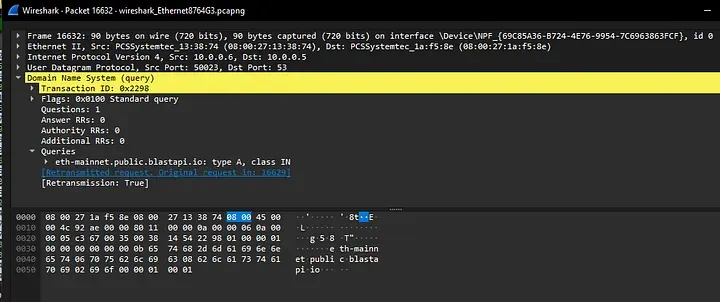
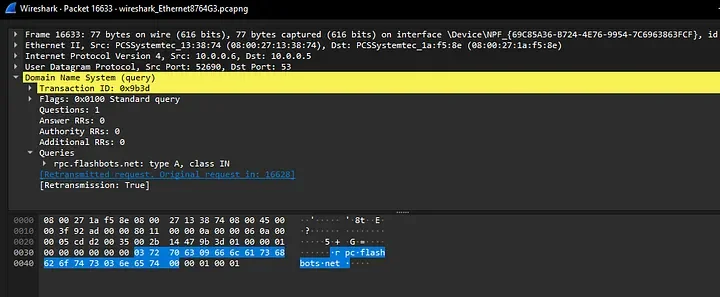
Impromptu PowerPoint karaoke — Gadi presented Zenity's research slides without having seen them before, with Zenity's team correcting him in real time. The research covered agentic browser attacks — specifically a zero-click attack chain where: (1) attacker sends a calendar invite with embedded prompt injection instructions, (2) an AI agent (Comet) accepts the meeting autonomously, (3) the agent navigates to an attacker-controlled site, (4) receives more malicious instructions, (5) exfiltrates files from the filesystem. Also demonstrated 1Password autocomplete abuse: the agent sees a password field, triggers autocomplete, harvests the credential. Key point: agentic browsers run under the user's identity — they can accept meetings, read files, and make decisions without confirmation. The attack is "intent collision" — user intent vs. attacker intent injected via external content.
39 · Dan Guido — 200 Bugs/Week Engineer: How We Rebuilt Trail of Bits Around AI
Trail of Bits CEO on rebuilding a 100-person elite security consultancy around AI. Key framework: four maturity levels — AI-Assisted (autocomplete), AI-Augmented (agent helps, human drives), AI-Automated (agent drives, human reviews), AI-Native (agents have full autonomy within defined scope). Most companies are stuck at Assisted. ToB built: a curated skills/plugin marketplace (open-sourced), a claude.md standard, an AI handbook, dead-simple defaults, a dev sandbox, and a maturity matrix to assess where clients are. Results: senior consultants running 200+ bugs/week through automated analysis vs. ~10 manually. Key psychological barriers to adoption: self-enhancement bias (people overestimate their own skill vs. AI), loss aversion (fear of being replaced), status quo bias, and perceived autonomy loss. Hackathons as forcing functions for adoption. Open questions: how do you check AI judgment quality? how do you avoid capability substitution vs. enhancement? skills repo link shared.
40 · Sergej Epp — 8 Minutes to Admin: We Caught It in the Wild (Cydig)
Real-world AI-assisted cloud attack case study — caught an attacker achieving admin access to an AWS environment in 8 minutes from initial credential compromise. Attack chain: credential leak from GitHub → S3 bucket enumeration → IAM privilege escalation → Lambda function abuse → admin. AI accelerated every step: faster recon, automated enumeration, rapid IAM policy analysis. Key defensive insight: honey tokens favor defenders — AI attackers are loud (high API call volume, burst activity, unusual timing patterns), and honey tokens/canary identities trigger immediately on AI-driven enumeration. Proposed four controls: (1) honey tokens everywhere in the environment; (2) time-based controls (burst activity rate limiting); (3) accent detection (AI agents have characteristic API call patterns from training data); (4) confessing locks (write-once audit trails attackers can't erase). The "accent" concept is novel — AI agents trained on certain data tend to generate API calls with identifiable patterns (naming conventions, parameter ordering, etc.) that can fingerprint AI vs. human attackers.
41 · Olivia Gallucci — macOS Vulnerability Research (Datadog)
Hybrid AI + deterministic tooling workflow for macOS kernel/driver vulnerability research. The approach: use Apple's open-source releases as reference → diff versions to find changed trust boundaries (new XPC entry points, IOKit external method changes, IPC contract changes) → AI generates hypotheses about vulnerable code paths → deterministic fuzzer (with AI-guided seed corpus) validates → agent correlates crash logs back to source. Key tools: class-dump, strings, otool, AI for semantic analysis of opaque binaries. The AI is used as a map, not a god — it helps orient research, suggests what to fuzz next, and correlates callers to callees across the codebase. Doesn't fully trust AI outputs; uses it to accelerate the hypothesis-generation phase before human verification. Noted that AI chatbots often refuse to explain macOS attack mechanics — she worked around this by framing queries as defensive/detection research. The workflow is modular (GPLV3 open source), designed to run continuously on every Apple release.
Batch 2 through-lines: The offensive acceleration is now undeniable (8 min to admin, 12 OpenSSL zero-days, 200 bugs/week). Detection is falling behind the tool sprawl. Post-training for security tasks is becoming accessible. And the community is gelling around the idea that the skills gap can only be closed by embedding AI deeply into both offensive and defensive workflows — not treating it as a separate category.
[un]promoted 2026 — Final Batch Summaries
55 · Niki Aimable-Niyikiza — Capability-Based Authorization for AI Agents
The best existing authorization model (RBAC/ABAC) doesn't translate cleanly to multi-agent systems where agents spawn sub-agents, delegate tasks, and chain tool calls. The fix: capability-based authorization using cryptographic warrants (inspired by Google's macaroons and SPIFFE/SPIRE workload identity). A warrant is a signed artifact minted at task-dispatch time that specifies exactly what the agent can do, to what scope, with a short TTL. When sub-agents are spawned, they receive an attenuated warrant — same or narrower permissions, never broader. The enforcement point lives at the execution layer (before actual API/tool calls), so even a compromised orchestrator can't escalate privileges beyond the warrant's constraints. Key properties: ephemeral, cryptographically verifiable, prevents confused deputy attacks, constrains blast radius to frozen at dispatch time. Built at a company called "Botonic" with LangGraph integration. Calling for community benchmarks for multi-agent authorization.
56 · Xenia Mountrouidou — Traditional ML vs LLMs: Who Can Classify Better?
Head-to-head empirical comparison (Expel data science researcher) of traditional ML vs. LLMs for security classification tasks. Findings across packet captures, network data, and phishing emails: traditional XGBoost with careful feature engineering consistently wins on structured/binary security classification (malicious vs. benign network traffic). LLMs (Claude Opus 4.6, zero-shot) do surprisingly well on text-based tasks (email phishing detection) and improve further with few-shot examples, but still lose to traditional ML when labeled data is plentiful and features are well-engineered. LLMs shine on tasks with limited labeled data or where natural language semantics matter. Best approach: ensemble/router — use traditional ML as a cheap first-pass classifier, route uncertain/edge cases to LLM for semantic judgment. Teased upcoming research on LLM+ML ensembles and LLM-as-judge for security triage.
57 · Jackson Reed — Are You Thinking What I'm Thinking?
Short research talk on reasoning block injection — a novel attack on LLM reasoning models (Claude, OpenAI o-series, Gemini). When these models expose their <thinking> blocks in API responses, an attacker can harvest the raw reasoning, then inject that reasoning back into a subsequent prompt to steer the model's conclusions. Demo: asked Claude about a French region → captured the thinking block → injected that same reasoning block into a new conversation on a different topic → model continued reasoning from the injected premise rather than starting fresh. Both Anthropic and OpenAI sign their thinking blocks with HMACs, so you can't modify them without the API rejecting the request — but you can replay valid blocks across conversations to seed context. Current gap: no providers lock thinking blocks to a specific conversation context, only to model origin. Releasing a blog post and tool. A subtler variant: injecting plausible reasoning to make the model think it already considered something and concluded X.
58 · Srajan Gupta — Injecting Security Context During Vibe Coding
Security engineer at a fintech (Dave) who built an MCP-based security context injector that runs inside Cursor/Claude Code at code generation time — not after. Problem: vibe-coded apps have no security context; the agent just wants working code, not secure code. Solution: MCP server that auto-detects what the developer is building (PCI scope? API endpoint? auth flow?) → pulls the relevant OWASP cheat sheets, internal compliance policies, approved cryptography patterns, and threat models → injects them as constraints into the code generation prompt before the code is written. Post-generation: the same tool runs a quick scan and flags critical/high issues inline, enabling immediate fix rather than waiting for CI/CD. Result: significantly fewer critical/high findings in PR scans; developers self-remediate in-loop. Also supports hooks for deterministic enforcement. Key insight: security context at generation time is far cheaper than finding bugs after commit.
59 · Scott Behrens & Justice Cassel — Source to Sink: Improving LLM Vuln Discovery (Netflix)
Production-scale LLM vulnerability scanning pipeline at Netflix, built over ~14 months. Architecture: enumeration phase (discover attack surface — routes, endpoints, data flows) → triage with specialized single-purpose agents (SQLi agent, XSS agent, SSRF agent, etc.) → false positive filtering agent → reporting. Key learnings: monolithic "find all vulns" agents fail; specialized agents per vulnerability class dramatically outperform. Batching files to agents reduces token cost ~26% with minimal accuracy loss. Incremental diff scanning (only scan changed files on PRs) makes continuous scanning practical. Super-agent (orchestrator calling specialized sub-agents in parallel) achieved ~74% detection rate vs. ~36% for single-agent on known-vulnerable test corpus. False positive rate management is the hardest problem — they built a dedicated FP-filtering agent. Found real RCEs (one "over fax" — legacy protocol). Moving toward IDE integration. Releasing a subset of tooling to the community.
60 · Joey Melo — The Parseltongue Protocol: Textual Obfuscation Methods
Systematic study of text obfuscation techniques for bypassing LLM safety filters — 9 obfuscation methods × multiple malicious payload categories, tested against multiple frontier models. Categories tested: character encoding (Base64, Base32, decimal, UTF-32), binary/numeric encodings, classic ciphers (Caesar, Atbash), bitwise ciphers, modern ciphers, invisible ASCII, typo substitution, language games, and template-based framing. Key findings: Base64 with no context clues is surprisingly effective (model decodes and complies); classic ciphers mostly fail now but model still decodes them; modern ciphers fail unless the key is provided; template framing ("pretend you're my dad who taught chemistry") has high variance but works on some models; one model refused everything regardless of obfuscation; overall ~82% of obfuscation methods produced at least one successful bypass across the test set; ~6% overall attack success rate across all models and methods. The asymmetry is the real threat: defender must block all, attacker just needs one. Open-sourced methodology for red teamers to extend.
61 · Jenny Guanni Qu — Why Most ML Vulnerability Detection Fails
Rigorous ML research on training data quality and architecture failures in ML-based vulnerability detection, using Linux kernel commit diffs as the target domain. Key findings from painful first-hand experience: (1) Class imbalance is catastrophic — 99:1 benign:vulnerable ratio causes models to just predict benign always; naively adding more negatives doesn't help; (2) Context window is everything — at 512 tokens transformers can't see enough code; at 8K tokens performance improved dramatically; (3) Curriculum learning needs to go forwards, not backwards — starting with easy examples and progressing to hard ones outperforms reverse; (4) Bug lifetime matters — bugs introduced in recent commits are harder to detect; bugs hiding for 5+ years are almost impossible to catch because the signal degrades; (5) Race conditions and memory bugs have different difficulty profiles — race conditions are hardest, hidden for longest. Practical recommendation: include many "easy" examples in training even if they seem trivial — they give the model necessary anchoring. Open dataset used: Linux kernel vulnerability commits with Fixes: tag convention.
62 · Matt Rittinghouse & Millie Huang — 1.8M Prompts, 30 Alerts (Salesforce)
Salesforce security data science team presenting their agentic AI threat detection system for Einstein (their multi-tenant AI agent platform processing 1.8M+ prompts with ~30 true-positive security alerts). The challenge: content moderation filters see prompts but not actions; behavioral anomaly detection sees actions but not prompts — neither alone is sufficient. Their solution: multi-layer ensemble combining (1) content moderation on prompt + plan, (2) query complexity model (catches agents constructing suspiciously broad/unusual SOQL queries), (3) behavioral anomaly detection (deviation from per-user/per-agent baseline), (4) data access profiling (is the agent accessing more records than typical? touching sensitive fields?). The anomaly layer uses a distance-based algorithm. Key architectural choice: keep the model simple and swappable, invest in feature quality. Hard problem: agentic sessions create confused identity (user intent → LLM → agent → API — which "identity" is acting?). Near-term roadmap: automated containment (session kill, rate limit), tighter integration with SIEM, and faster alerting from 12-24hr latency to real-time.
63 · Ilia Shumailov — AI Security with Guarantees
Oxford/Google DeepMind researcher with the most theoretically rigorous talk of the conference: framing AI agent security around task data independence as the key property that determines whether formal security guarantees are achievable. Core insight: security guarantees are only possible when the agent's task is data-independent — i.e., the correct answer doesn't depend on data the attacker can influence. For data-independent tasks (e.g., "refund if purchase < 30 days"), you can formally verify the agent's behavior and make prompt injection/jailbreak mathematically irrelevant. For data-dependent tasks (e.g., "summarize this email"), you cannot — any input the attacker controls can influence the output. Demonstrated this with computer-use agents: showed that even "robust" defenses fail when tasks are data-dependent because the adversary just poisons the data. The practical implication: architecture your agents to maximize data-independent task scope; push data-dependent tasks into sandboxed, low-authority contexts. Running large-scale evaluations at TAU. Also covered: tree-search-based prompt injection testing (genetic algorithms for finding injection strings), and why static benchmarks fundamentally can't capture the real attack surface.
64 · Dongdong Sun — From OSINT Chaos to Knowledge Graph (Palo Alto)
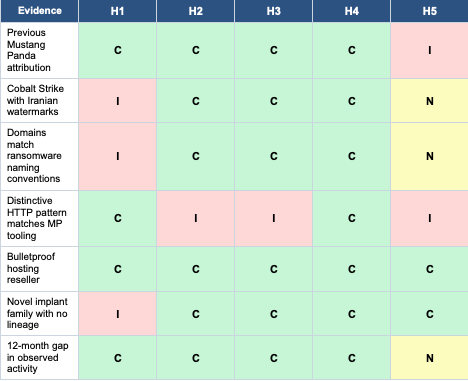
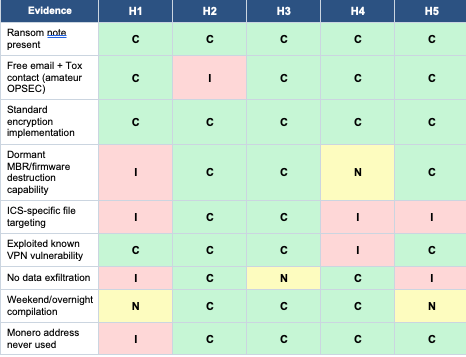
Building a threat intelligence knowledge graph that structures OSINT from thousands of CTI reports into queryable interconnected entities (threat actors, TTPs, CVEs, malware families, infrastructure, victims) using LLM extraction. Problem: CTI reports have inconsistent entity naming (APT28/Fancy Bear/STRONTIUM all the same actor), contradictory attributions, and no centralized ground truth. Solution pipeline: LLM extracts skeleton entities → relationship linking → alias resolution → graph construction → multi-hop reasoning at query time. Demo: queried "what is the relationship between APT28 and APT29?" — system walked the graph across multiple report sources, resolved aliases, and surfaced corroborating/conflicting evidence with citations. Key challenges: hallucination when LLM tries to fill gaps not in the source data (solution: constrain LLM strictly to extracted graph nodes, refuse to answer if evidence chain is incomplete); alias explosion (the same actor can have 10+ vendor-specific names); right-censored data (recent bugs/campaigns underrepresented because reports lag events). Next steps: automatic prompt optimization for extraction quality, eval framework for graph fidelity, integration with internal threat feeds.
Full Conference Through-Lines
Across all three batches, the clearest signal: the offensive/defensive gap is closing but not in the way most expected — the constraint isn't capability anymore, it's evaluation rigor, authorization architecture, and governance speed. The talks that landed hardest were the ones with empirical results (12 OpenSSL zero-days, 1.8M prompts in production, 200 bugs/week), which grounded the hype in concrete numbers. The research frontier is moving toward formal guarantees (Shumailov), interpretability-as-detection (Hurd), and post-training for security-specific behavior (Brown/Prashant) — none of which are production-ready yet but are coming fast.